Hackeando o acesso a dados não centralizados - Parte 1
2022-11-15
David Pierre
As informações sobre os níveis de sangue no Brasil, apesar de existentes, não são acessíveis, tampouco centralizadas. Como podemos utilizar a tecnologia para democratizar e facilitar o acesso à dados descentralizados e não-uniformes?
Há alguns anos atrás, uma grande amiga minha adoeceu e precisou receber doação de sangue para seu tratamento. Foi uma grande comoção. Afinal, era comum que os bancos de sangue estivessem com o estoque baixo para pelo menos um tipo de sangue. Geralmente eu sabia sobre o baixo estoque através de redes sociais, principalmente de pessoas que estavam acompanhando o tratamento mais de perto. Foi ai que pensei: esses dados eles devem ser acessíveis de alguma forma, certo?

Comecei a pesquisar os bancos de sangue de minha cidade, para ver o que eu poderia encontrar. Tentei todas as opções que me vieram à mente: APIs, Lei de Acesso a Informação, Planilhas, qualquer coisa que me ajudasse a ter esses dados em mão de forma "pronta". Já estava prestes a desistir. Foi quando encontrei uma seção interessante na página inicial de alguns desses bancos.
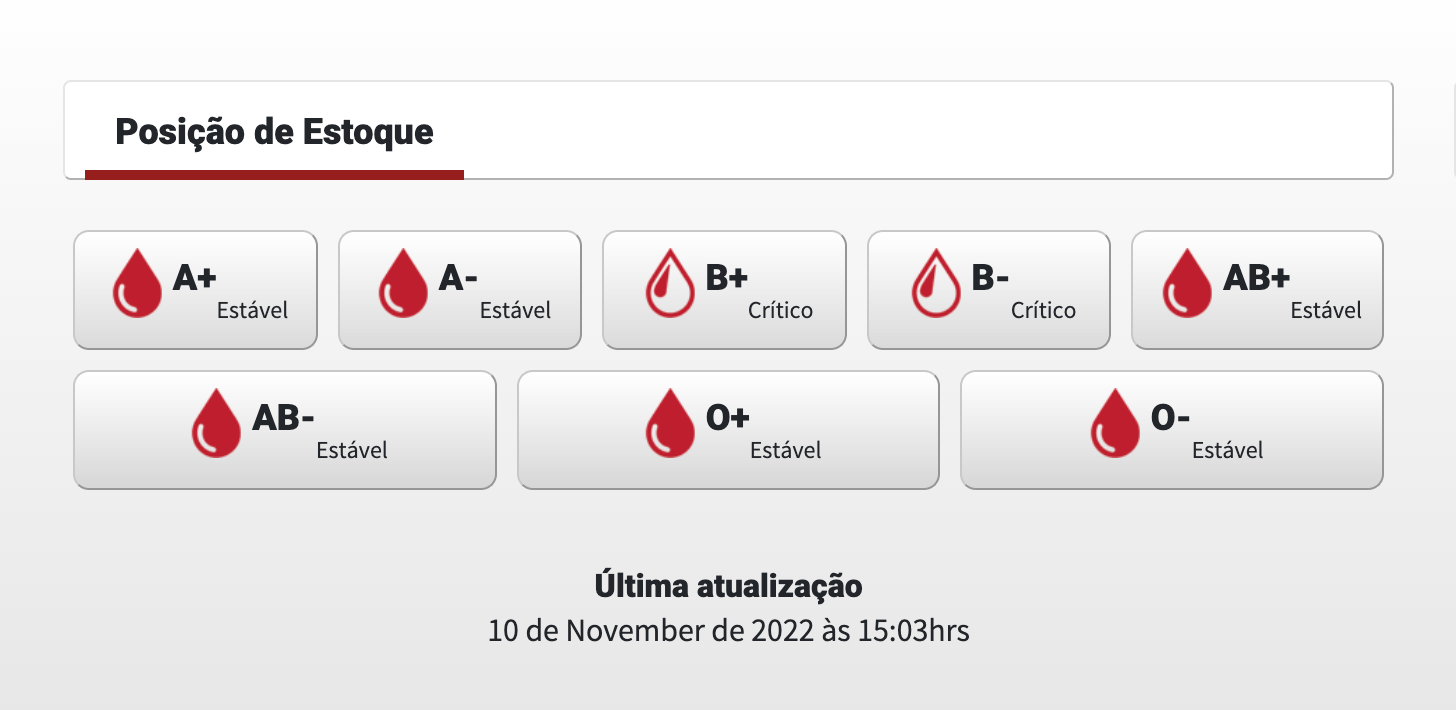
O dado estava ali. Mas os dados (histórico, formatado, etc) não eram disponibilizados facilmente. Então, decidi que eu mesmo coletaria os dados que eu queria. Já possuia alguma experiência com raspagem de dados, então não seria complexo automatizar a coleta desses níveis de sangue.
Fiz o mapeamento de alguns bancos de sangue locais que possuíam alguma seção que mostrasse o nível de sangue de seus estoques. Afinal, não teria sentido analisar a coleta de um único site. A ideia era simples: coletar o maior número de dados possível, de diferentes locais, e centralizar, de forma que facilite ao doador de sangue saber quando ele pode doar, onde os estoques estão mais baixos e democratizar a situação dos estoques disponíveis, até para ajudar em outras campanhas de doação de sangue.
Comecei o projeto. criei os raspadores para alguns dos bancos de sangue encontrei. E assim nasceu o Sanguine. Sanguine é um projeto iniciado em 2018 e é um eterno projeto em andamento, tem seus raspadores feitos usando Scrapy e uma API construída em Flask. Como o projeto acabou virando um projeto legado, há uns meses, tive que reestruturar algumas coisas, para facilitar a configuração e execução do projeto. Atualizei as dependências, os raspadores, coloquei o projeto em conteineres, refatorei as rotas e a API, criei uma tarefa rotineira para que pudesse coletar os dados automaticamente. E o intuito desse post é mostrar como contribuir para o projeto, mostrando como rodar o projeto, criar seu próprio raspador e criando seu Pull Request no Github.
# Executando o projeto
Antes de tudo, é importante que você tenha instalado, em sua máquina, git, Docker e Docker-Compose. Apesar de ser possível executar o projeto diretamente em sua máquina, o uso de conteineres Docker facilitam a instalação de dependências e reduz possíveis erros de ambiente, já que temos um ambiente virtualizado.
Clonando o repositório
O Sanguine está hospedado no Github, uma plataforma de versionamento de código, que utiliza git. Para baixar o projeto para sua máquina, é possível utilizar a linha de comando git para se comunicar com o repositório remoto, então, no diretório que você quer que o projeto esteja localizado, execute o seguinte comando:
git clone https://github.com/davidpalves/sanguine-scrapy.git
Uma vez que o projeto foi clonado localmente, você pode acessá-lo navegando para o diretório do projeto
cd sanguine-scrapy
Montando o projeto
Caso você esteja usando um sistema UNIX ou WSL no Windows, você provavelmente pode executar comandos descritos no Makefile. Caso não, você pode abrir o Makefile do projeto em um editor de texto e rodar, manualmente, os comandos descritos lá.
No diretório raíz do projeto, é preciso configurar nossas variáveis de ambiente: geralmente são variáveis sensíveis e/ou mutáveis, que estão exemplificadas no arquivo .env.example. Duplique este arquivo e renomeie o novo arquivo para .env . Note que este arquivo não deve ser versionado, é um arquivo pessoal que contém credenciais para o projeto.
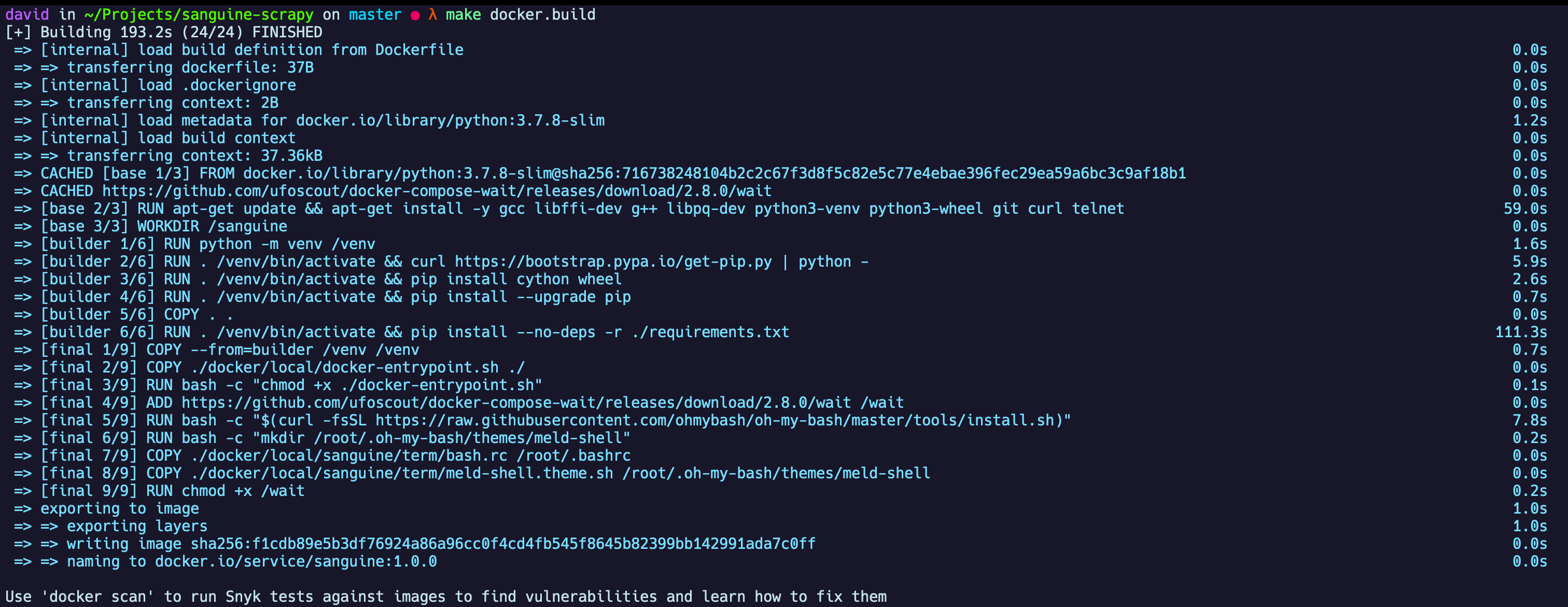
Agor, vamos construir nossa imagem Docker. Isso vai fazer com que baixemos as imagens e dependências necessárias descritas no Dockerfile e no arquivo do Compose. Para construir nossa imagem, vamos executar o seguinte comando:
make docker.build
Ao terminar a execução do comando, o terminal deve ter uma saída parecida com esta:
Executando o projeto
Agora, com nossa imagem construída, podemos simplesmente rodar o projeto agora e verificar que tudo está executando corretamente. Para isso, utilize o comando:
make docker.run
E podemos ver os registros de nossos conteineres rodando, e nos certificar que tudo foi ligado corretamente.
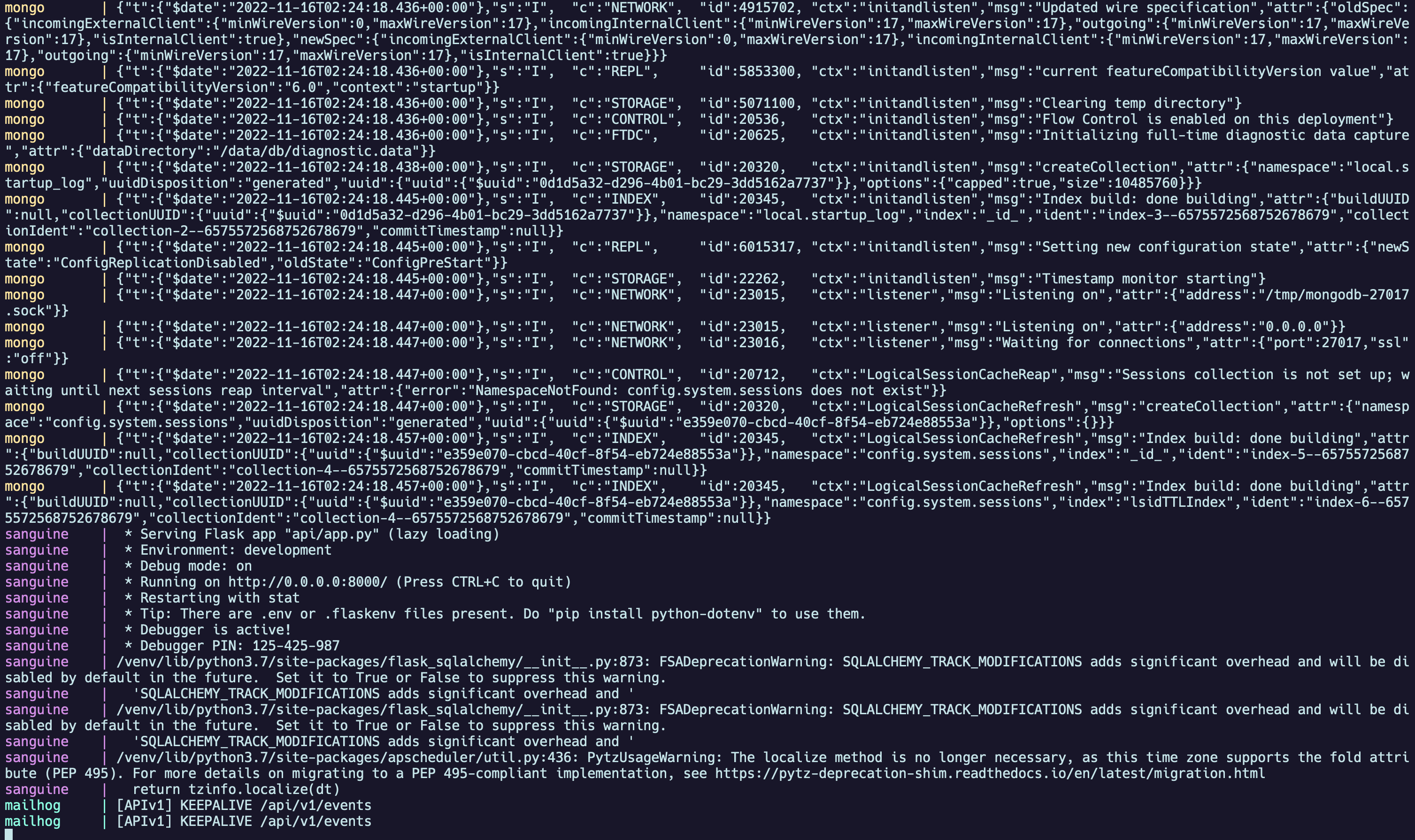
Como podemos observar, é possível ver que a API, com o nome sanguine, já está rodando corretamente na porta 8000 em nossa máquina local. Se tentarmos acessar o endereço http://locahost:8000, vamos nos deparar com um JSON vazio.
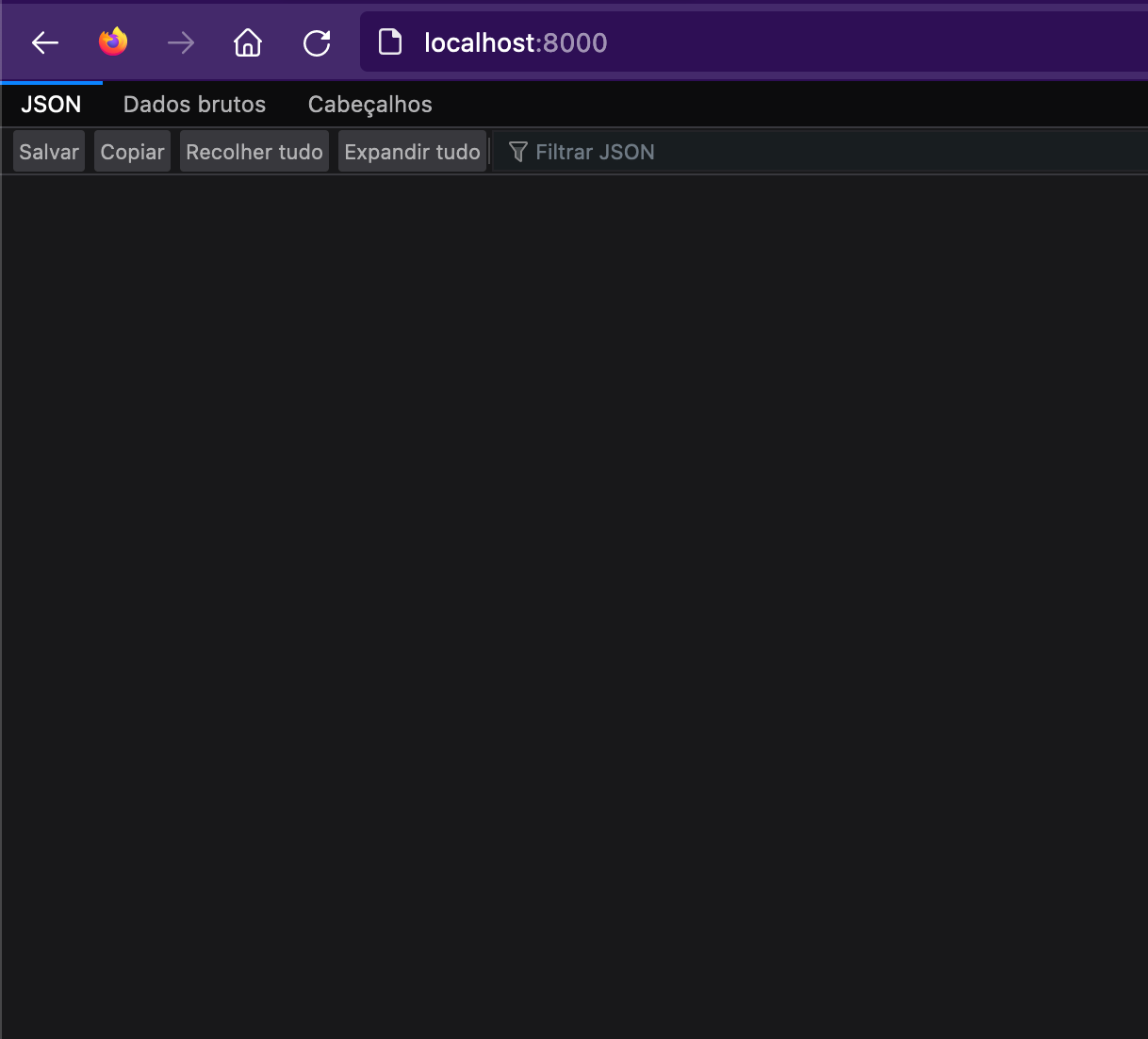
Populando os dados do projeto
Isso acontece porque ainda não populamos nossa base de dados. Ainda não raspamos, propriamente, os dados dos sites de bancos de sangue. Para fazer isso, vamos acessar o shell do conteiner, utilizando:
make docker.shell
Ao acessar o shell de nosso conteiner, vamos nos deparar com o seguinte shell
Agora, podemos executar comandos diretamente em nosso conteiner Docker, com todas as dependências do projeto já instaladas. Já criei, anteriormente, alguns atalhos para rodar todas as nossas Spyders (raspadores) de uma vez. Podemos tanto utilizar o script Python dentro da raiz do projeto para isso, executando
python ./run.py
Ou indo até a pasta da API e executando um comando definido através do Flask. Seria algo parecido com isso:
cd api/ && flask data update
A única diferença é que o comando do script Python, vai rodar de forma silenciosa, suprimindo os logs. Enquanto o comando Flask vai mostrar os registros da saída de nossos raspadores.
Acessando os dados obtidos
Agora que já executamos o projeto, já rodamos nossos raspadores e garantimos que tudo está funcionando de forma correta, podemos acessar os dados. Como já vimos anteriormente, nossa API está executando na porta 8000 de nossa máquina local. Então, vamos ver o que obtivemos. Acessando o endereço http://localhost:8000 veremos lá os dados coletados.
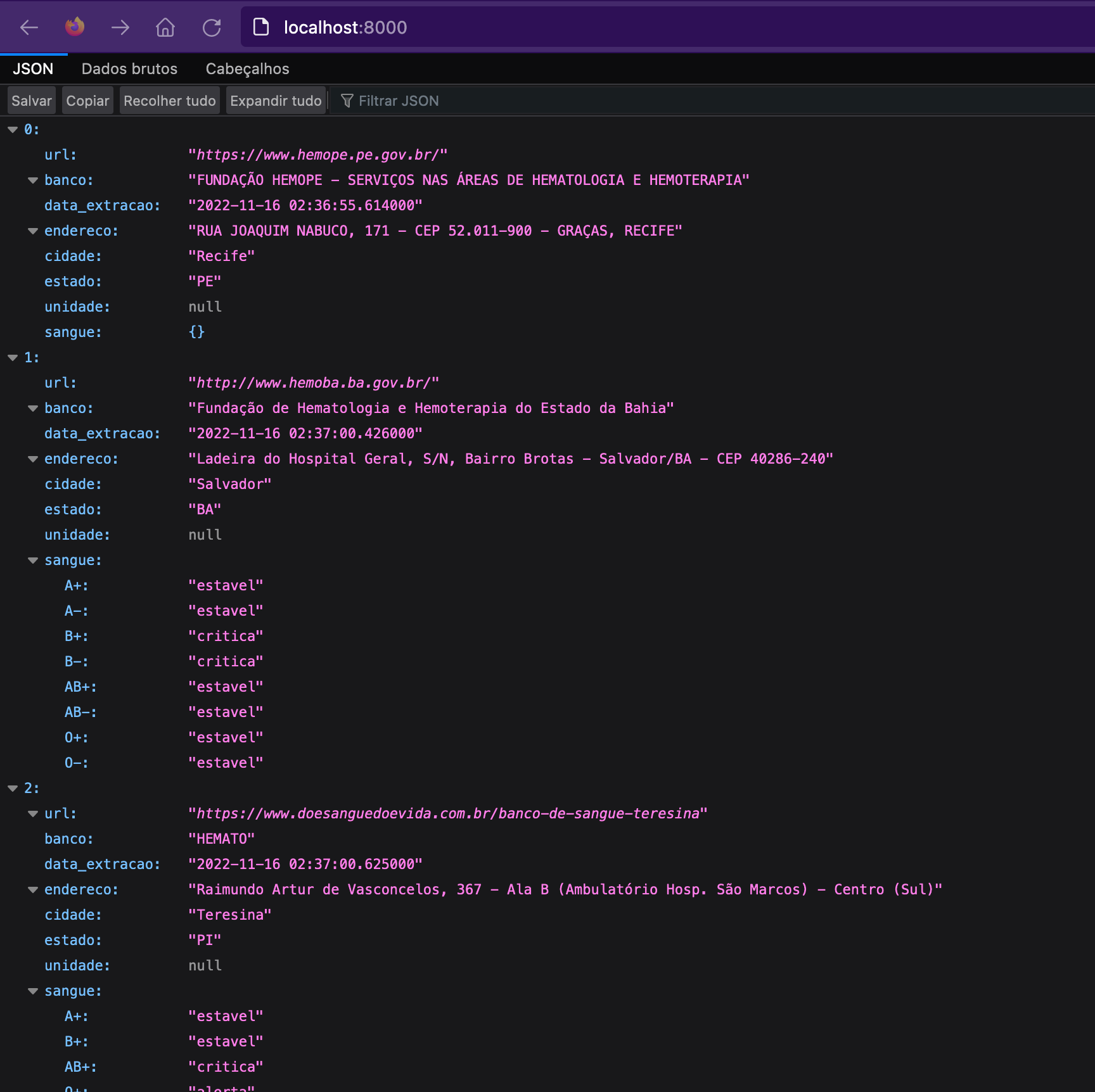
Como todo dado raspado da Internet, é possível que por alguma mudança no site, nossos raspadores parem de funcionar corretamente, ou que alguma informação tenha sido removida do site em questão. Por isso, não se assuste caso algum desses bancos de sangue não possua as informações dos níveis de sangue.
Conclusão
Nessa primeira parte de nossa série sobre Sanguine, pudemos introduzir como executar o projeto localmente, a obter os dados dos raspadores e como acessar esses dados através da API Flask do projeto. Nas próximas partes veremos como criar novos raspadores e como contribuir ativamente para o projeto. Você também pode seguir este mesmo passo-a-passo lendo as instruções do próprio projeto.